
Language identification setup basics
This quick reference guide contains a basic workflow for identifying the languages used in your documents. For more detailed information, see Analytics.
Language identification setup
The setup for running language identification is comprised of three components:
-
Saved search
-
Structured analytics set
-
View
1. Saved Search Setup
Use the following conditions and fields to create the saved search used for language identification. You do not need to set a sort order on this search.
-
Search Name—there is no recommendation for the saved search name. Follow your team’s normal protocol for naming searches.
-
Conditions—extracted text size is greater than 0KB.
-
Fields—any fields are acceptable.
2. Structured Analytics Set
Here are the steps and choices for creating a structured analytics set.
-
Name—enter a name for the structured analytics set.
-
Prefix—keep the default prefix or add your own prefix. Shorter prefixes (even just two characters, such as “LI”) take up less space in your views.
-
Operations to run—select Language identification.
-
Data source—select the saved search you created above.
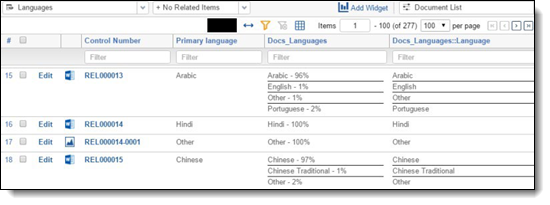
3. Language ID view
Once you run the structured analytics set, create the following view to see the results of your language identification operation.
-
Fields
-
Control Number
-
[SAS Prefix]::Primary Language
-
[SAS Prefix]::Docs_Languages
-
[SAS Prefix]::Docs_Languages:Language
-
-
Conditions—[SAS Prefix]::Primary Language is set
-
Sort—you do not need a specific sort order for this view. However, you can create separate searches and views for each document set as well as widgets and dashboards.